The transformation of enterprises through artificial intelligence is in full swing. Yet AI systems are only as good as the data they are fed. While many organizations still struggle with fragmented, centrally managed data systems, a new generation of architecture patterns is emerging—patterns specifically designed for the requirements of AI-driven organizations. These patterns address a central challenge: How can we provide data in a decentralized, high-quality, and real-time manner without sacrificing controllability and governance?
Data Mesh: Decentralization with Federated Control
The most revolutionary concept in recent years is undoubtedly Data Mesh Architecture. It challenges the classical model of centralized data lakes and data warehouses, replacing it with domain-oriented decentralization. As Martin Fowler outlines in his comprehensive guide to Data Mesh principles, responsibility for data shifts from a central platform to the business domains themselves.
The core principles of Data Mesh rest on four fundamental pillars:
Domain-Oriented Decentralization
Instead of a central data platform managing all analytical data, responsibility is shifted to the business domains themselves—think sales, risk management, compliance. These teams understand their data best, grasp the business logic, and can adapt to changes faster. For AI projects, this is a tremendous advantage: Data Scientists can work directly with domain experts to develop features that are truly business-relevant.
Data as a Product
Data is no longer treated as a byproduct of ETL processes, but as a fully-fledged product with quality guarantees, documentation, and service-level agreements. Each domain-data product owner bears responsibility for data quality, availability, and usability. This creates real incentives for high-quality data provisioning—a prerequisite for successful AI models.
Self-Service Data Infrastructure
The ability for teams to independently build, test, and deploy their data pipelines is crucial. A central platform provides standardized tools, APIs, and workflows without requiring deep specialist knowledge. Domain teams can therefore experiment and iterate faster.
Federated Computational Governance
Despite decentralization, there are global standards and policies that are automatically enforced by the platform. This ensures interoperability between data sources, compliance adherence, and secure data usage—a critical point for regulated financial institutions and other heavily controlled industries.
Benefits for AI: Data Mesh enables faster development cycles, reduces silos, and creates a network effect where data products can be combined. At the same time, control is maintained through decentralized governance mechanisms. Google Cloud’s architecture documentation demonstrates how data mesh principles scale across global enterprises.
Data Fabric: The Intelligent Integration Layer
While Data Mesh focuses on decentralization, Data Fabric takes a somewhat different approach. It creates an AI-powered, intelligent integration layer that virtually connects distributed data across various systems and cloud environments—without physical duplication.
The essential components:
Data Virtualization: Applications transparently access data sources without knowing where they are physically stored. This reduces data silos and enables faster data access for analytical workloads.
Active Metadata Management: Modern Data Fabrics leverage Machine Learning to automatically capture, classify, and analyze metadata. This enables automated data quality checks, lineage tracking, and governance enforcement.
Automation Through ML: Integration processes, data cleansing, access control, and compliance monitoring are increasingly automated. A system learns from patterns and can proactively identify potential issues.
Benefits for AI: Data Fabric dramatically reduces the time needed for data access and data preparation—a classic bottleneck in ML projects. Through governance automation, data teams can focus on higher-value tasks.
Data Lakehouse: The Best of Both Worlds
The Data Lakehouse Architecture combines the flexibility and cost efficiency of Data Lakes with the structured control and performance of Data Warehouses—specifically optimized for AI/ML workloads. Databricks, pioneers of the lakehouse architecture, describe how unified data foundations reduce pipeline complexity by 60-70%.
The Architecture in Detail
Storage Layer: Cloud-native, infinitely scalable storage in open formats such as Parquet, Delta Lake, or Apache Iceberg. These formats allow multiple tools and frameworks to simultaneously access the same data.
Management Layer: ACID transactions guarantee data consistency, even when multiple processes modify data simultaneously. Schema enforcement ensures data quality, versioning allows rollbacks and auditability, and data lineage shows exactly how data originated.
Processing Layer: The revolutionary aspect of the Lakehouse architecture is that a single data foundation can be used for batch processing, streaming analytics, SQL queries, and machine learning. This eliminates cumbersome ETL processes between multiple systems.
Practical Benefits: Organizations report 60-70% reduction in pipeline complexity, 25-35% lower total costs, and significantly faster time-to-insight for Data Science teams.
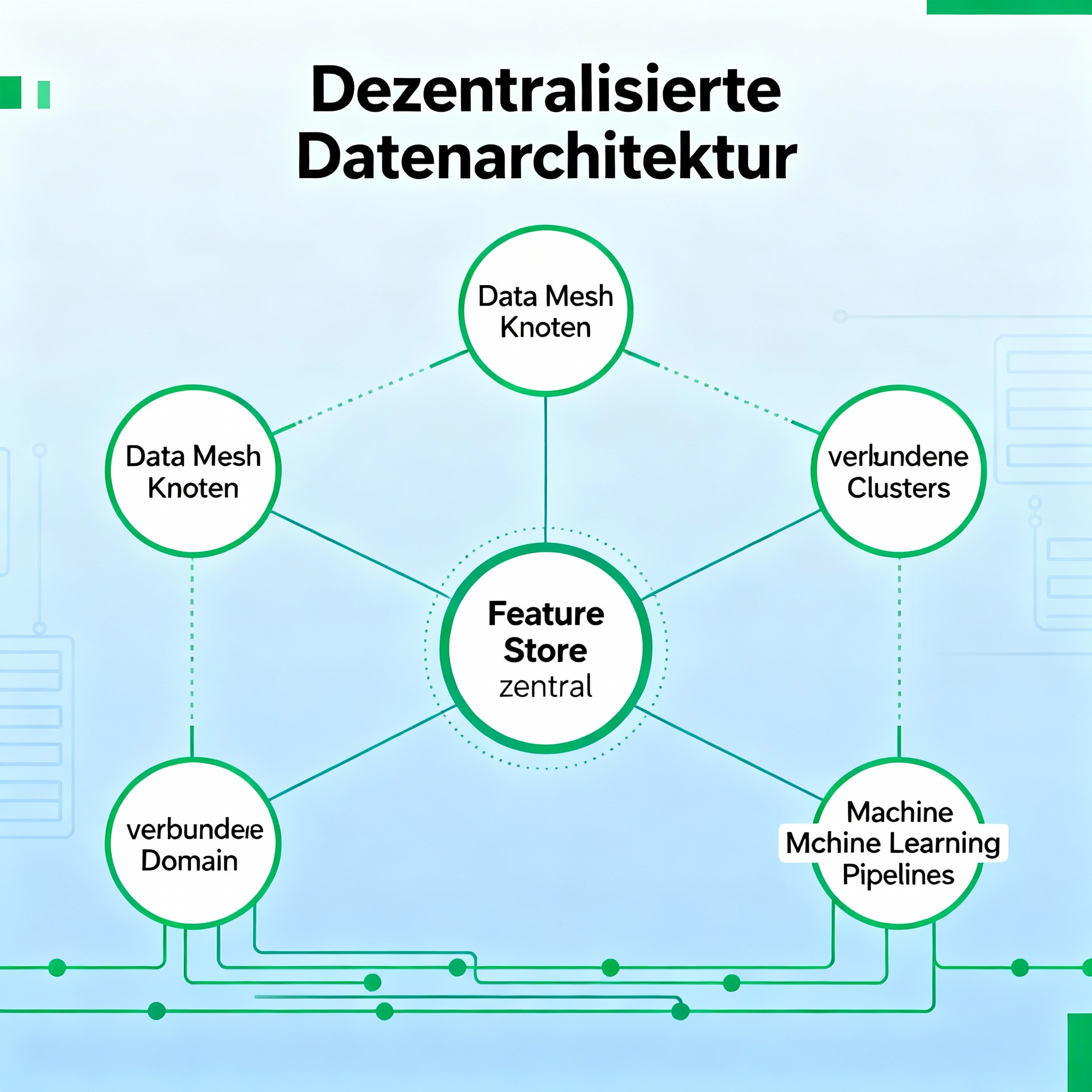
Feature Store: The Backbone of Productive ML
While Data Mesh, Data Fabric, and Lakehouse form the infrastructure, the Feature Store is the layer that specifically optimizes ML systems. A Feature Store is a central repository for machine-learning-relevant features—predefined, calculated data aspects used in ML models.
Why is a Feature Store Critical?
In practice, Data Scientists encounter a classic problem: the features used during model training differ from those available at deployment. This leads to the so-called training-serving skew, a frequent source of degrading model performance in production.
A Feature Store solves this through:
Offline Store: Historical feature data for batch training and backtesting.
Online Store: High-performance, low-latency storage for real-time inference (predictions).
Feature Registry: Central metadata management, versioning, documentation, and discovery.
Transformation Engine: Automated pipelines for feature calculation that run consistently between training and serving.
Modern feature store platforms such as Tecton, Feast, and Hopsworks provide production-ready solutions for managing ML features at scale.
Point-in-Time Joins and Data Leakage Prevention
An additional, subtle but highly critical advantage: Feature Stores can ensure that when assembling training data, no future information “leaks into the past”—a frequent problem that leads to overly optimistic models that fail in reality.
Real-Time Feature Engineering for Time-Critical AI
Many modern AI applications require immediate decisions: Fraud detection must identify suspicious transactions in milliseconds. Personalization systems must consider user preferences in real-time. This is where Real-Time Feature Engineering comes in.
The Architecture
Stream Processing: Continuous data processing with tools like Apache Kafka, Flink, or Spark Streaming, which process events immediately rather than collecting and processing them later.
Sliding Window Aggregations: Features are calculated over rolling time windows—for example, the average transaction amount over the last hour or the number of logins in the past 15 minutes.
Stateful Computations: Context between individual events is preserved—critical for pattern recognition or anomaly detection.
Sub-Second Serving: Feature requests are answered in under a second, enabling real-time-based decisions.
Challenges
Real-time features are non-trivial: data may arrive out-of-order, systems must handle traffic spikes, and feature freshness must be monitored. Databricks’ best practices for real-time feature computation address these critical challenges.
MLOps Pipelines: The Nervous System of AI in Production
MLOps (Machine Learning Operations) is the discipline that integrates data pipelines, model training, deployment, and monitoring into automated, continuous workflows. This is equivalent to DevOps but specifically for machine learning processes. MLOps.org outlines the core principles for operationalizing machine learning systems.
Core Components
Data Versioning & Orchestration: Similar to version control for code—but for data. Tools like Apache Airflow orchestrate complex workflows across multiple systems.
Model Registry: Trained models are versioned, documented, and tagged with metadata. Teams can understand which model ran in production at what time and perform rollbacks when needed.
CI/CD for ML: Continuous Integration and Continuous Delivery—automated tests that ensure a new model is not worse than the old one before deployment.
Monitoring & Observability: Permanent monitoring of model performance, data quality, and drift detection. When input data changes dramatically, the team is proactively notified.
Architecture Variants
Lakehouse-Based: A unified platform for DataOps, MLOps, and ModelOps—all on the same physical foundation.
Lambda/Kappa Architecture: Combination of batch processing for historical analysis and real-time processing for immediate insights.
Event-Driven Architecture: ML workflows are triggered by events—for example, automatically retraining a model when new training data becomes available.
AI Governance and Data Governance Integration
As AI adoption increases, a new challenge emerges: How do I govern AI systems? This is not just a technical problem but an organizational one.
The New Governance Reality
Classical Data Governance was often top-down: A central team defined what was “right,” certified certain datasets as “golden,” and controlled everything. This resulted in silos and delays.
AI + Data Governance 2.0 works differently:
Federated AI Governance: Decentralized teams make decisions with global, automated policy enforcement mechanisms. A Data Product Owner decides how their dataset is defined but must adhere to global standards (e.g., data privacy, compliance).
Real-Time Compliance Monitoring: Automated systems continuously monitor whether policies are being followed—data accesses are logged, suspicious patterns trigger alerts.
Automated Auditability: AI systems independently generate audit trails—who accessed which data, how were features defined, which model version is in production?
Transparency and Explainability: Not just technically but also organizationally: stakeholders can understand why an ML model made a specific decision.
Practical Implementation: From Theory to Practice
Step 1: Mapping the Current State
Before implementing anything, an organization must understand: Where is data already located? Which AI/ML systems exist? Where are the biggest silos?
Step 2: Identifying Domains
Which business domains exist in the organization? These later become Data Products.
Step 3: Selecting the Technology Stack
Data Mesh, Data Fabric, and Lakehouse are concepts, not concrete products. Technologies like Apache Spark, Databricks, Snowflake, dbt, Great Expectations, and others are combined. Microsoft’s Azure Architecture Center provides detailed reference architectures for building AI/ML systems at scale in the cloud.
Step 4: Pilot Projects
Don’t transform the entire organization at once. Start with one or two domains, gather lessons learned.
Step 5: Establishing a Governance Framework
Before too many AI systems run wild, establish a governance framework. Enterprise architecture platforms like LeanIX support this effort by providing visibility into AI systems and enabling enforcement of governance policies at scale.
Business Impact
Organizations that correctly implement these modern architecture patterns report:
-
30-50% faster time-to-market for new AI/ML products
-
40-60% reduction in data engineering costs through automation
-
Higher data quality through domain ownership and dedicated data products
-
Better compliance through automated, auditable governance
-
Scalability: From a handful of AI projects to hundreds, while complexity decreases
Conclusion: The New Normal
The future of data management in the AI context is decentralized, automated, and governance-oriented. Organizations still clinging to monolithic data lakes or centralized data warehouses won’t keep up—not because of the technology, but because the organizational structure doesn’t scale.
Data Mesh, Data Fabric, Lakehouse, Feature Store, and MLOps are not mere technological gimmicks. They are enablers for an organization to use AI quickly, scalably, and responsibly. Companies that understand this will shape the next decade.
The journey begins with honest self-analysis: Where does our organization stand today? And where do we want to be tomorrow?


