Die Transformation von Unternehmen durch künstliche Intelligenz ist in vollem Gange. Doch KI-Systeme sind nur so gut wie die Daten, die ihnen zur Verfügung stehen. Während viele Organisationen noch mit fragmentierten, zentral verwalteten Datensystemen kämpfen, zeichnet sich eine neue Generation von Architekturmustern ab, die speziell für die Anforderungen von KI-gestützten Organisationen entwickelt wurden. Diese Muster adressieren eine zentrale Herausforderung: Wie schafft man es, Daten dezentralisiert, hochwertig und in Echtzeit bereitzustellen – ohne dabei Kontrollierbarkeit und Governance zu verlieren?
Data Mesh: Die Dezentralisierung mit föderaler Kontrolle
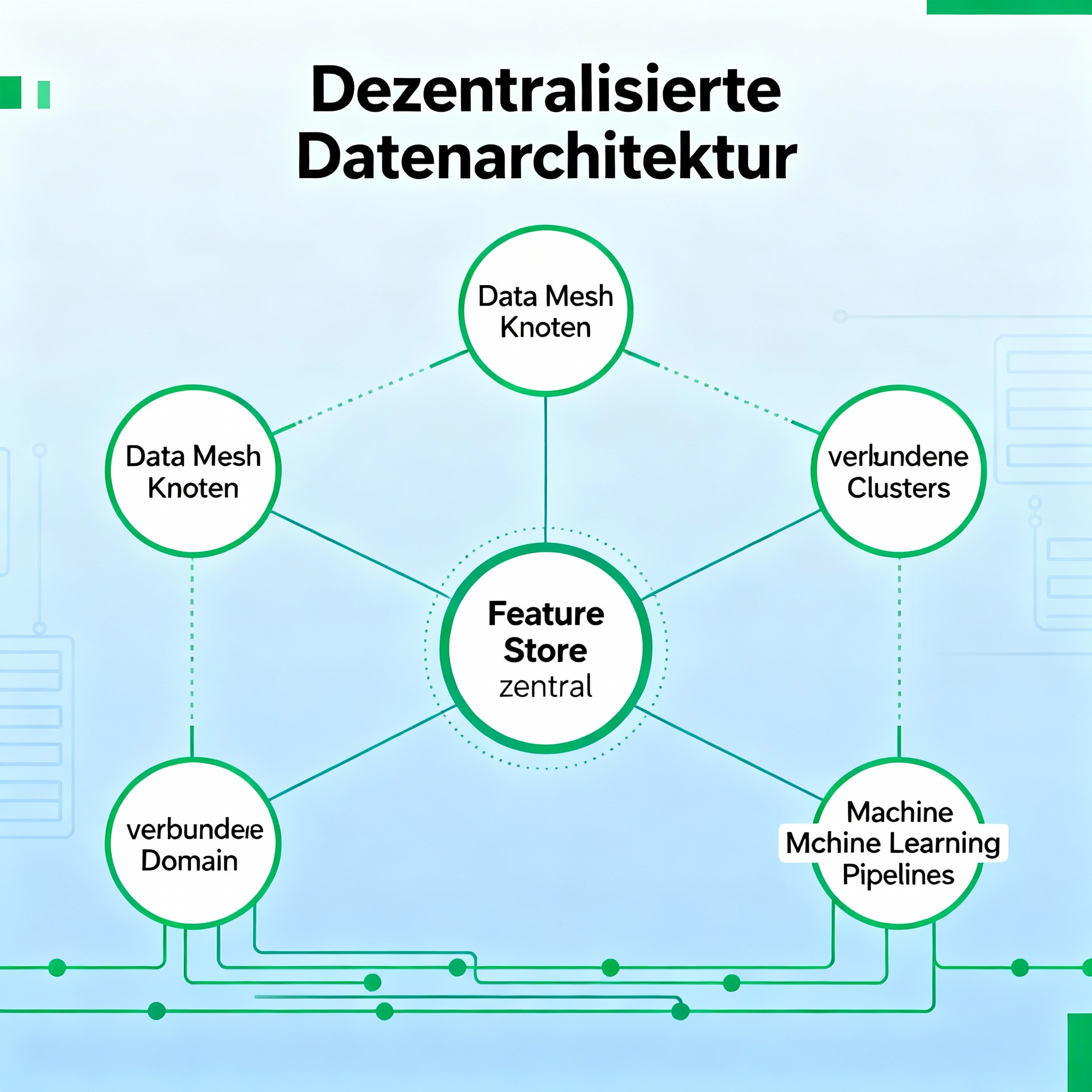
Das revolutionärste Konzept der letzten Jahre ist zweifellos die Data Mesh Architecture. Sie stellt das klassische Modell der zentralisierten Data Lakes und Data Warehouses in Frage und ersetzt es durch eine domänenorientierte Dezentralisierung. Wie Martin Fowler in seinem umfassenden Leitfaden zu Data Mesh Prinzipien ausführlich beschreibt, verlagert sich die Verantwortung für Daten von einer zentralen Plattform hin zu den fachlichen Domänen selbst.
Das Kernprinzip der Data Mesh basiert auf vier fundamentalen Säulen:
Domain-Oriented Decentralization
Statt dass eine zentrale Datenplattform alle analytischen Daten verwaltet, werden diese in die Verantwortung der fachlichen Domänen (beispielsweise Vertrieb, Risikomanagement, Compliance) übertragen. Diese Teams kennen ihre Daten am besten, verstehen die Business-Logik und können schneller Veränderungen umsetzen. Für KI-Projekte ist dies ein enormer Vorteil: Data Scientists können direkt mit den Domain-Experten zusammenarbeiten und Features entwickeln, die wirklich geschäftsrelevant sind.
Data as a Product
Daten werden nicht als Nebenprodukt von ETL-Prozessen behandelt, sondern als vollwertige Produkte mit Qualitätsgarantien, Dokumentation und Service-Level-Agreements. Jede Domain-Datenprodukt-Owner trägt Verantwortung für Datenqualität, Verfügbarkeit und Benutzerfreundlichkeit. Dies schafft echte Anreize für hochwertige Datenbereitstellung – eine Voraussetzung für erfolgreiche KI-Modelle.
Self-Service Data Infrastructure
Die Fähigkeit für Teams, eigenständig ihre Datenpipelines zu bauen, zu testen und bereitzustellen, ist entscheidend. Eine zentrale Plattform stellt standardisierte Tools, APIs und Workflows bereit, ohne dass tiefes Spezialistenwissen notwendig ist. Domänenteams können dadurch schneller experimentieren und iterieren.
Federated Computational Governance
Trotz Dezentralisierung gibt es globale Standards und Policies, die automatisch durch die Plattform durchgesetzt werden. Dies gewährleistet Interoperabilität zwischen Datenquellen, Compliance-Einhaltung und sichere Datennutzung – ein kritischer Punkt für regulierte Finanzunternehmen und andere stark kontrolierten Branchen.
Vorteile für KI: Data Mesh ermöglicht schnellere Entwicklungszyklen, reduziert Silos und schafft einen Netzwerkeffekt, bei dem Datenprodukte kombiniert werden können. Gleichzeitig bleibt die Kontrolle durch dezentralisierte Governance-Mechanismen erhalten. Googles Cloud Architecture zeigt praktische Implementierungen dieser Prinzipien.
Data Fabric: Die intelligente Integrationsschicht
Während Data Mesh auf Dezentralisierung setzt, nimmt Data Fabric einen etwas anderen Ansatz. Sie schafft eine KI-gestützte, intelligente Integrationsschicht, die verteilte Daten über verschiedene Systeme und Cloud-Umgebungen hinweg virtuell verbindet – ohne physische Duplizierung.
Die wesentlichen Komponenten:
Data Virtualization: Anwendungen greifen transparent auf Datenquellen zu, ohne zu wissen, wo diese physisch gespeichert sind. Dies reduziert Datensilos und ermöglicht schnelleren Datenzugriff für analytische Workloads.
Active Metadata Management: Moderne Data Fabrics nutzen Machine Learning, um Metadaten automatisch zu erfassen, zu klassifizieren und zu analysieren. Dies ermöglicht automatisierte Datenqualitätsprüfungen, Lineage-Tracking und Governance-Enforcement.
Automation durch ML: Integrationsprozesse, Datenbereinigung, Zugriffskontrolle und Compliance-Überwachung werden zunehmend automatisiert. Ein System lernt von Mustern und kann potenzielle Probleme proaktiv erkennen.
Vorteile für KI: Data Fabric reduziert erheblich die Zeit für Datenzugriff und Datenaufbereitung – ein klassisches Bottleneck in ML-Projekten. Durch die Automatisierung von Governance können Data Teams sich auf höherwertige Aufgaben konzentrieren.
Data Lakehouse: Die beste beider Welten
Die Data Lakehouse Architecture verbindet die Flexibilität und Kosteneffizienz von Data Lakes mit der strukturierten Kontrolle und Performance von Data Warehouses – speziell für KI/ML-Workloads optimiert. Databricks, die Pioniere der Lakehouse-Architektur, beschreiben, wie vereinheitlichte Datenfundamente die Pipeline-Komplexität um 60-70% reduzieren.
Die Architektur im Detail
Storage Layer: Cloud-native, unbegrenzt skalierbare Speicherung in offenen Formaten wie Parquet, Delta Lake oder Apache Iceberg. Diese Formate erlauben es, dass mehrere Tools und Frameworks gleichzeitig auf die gleichen Daten zugreifen.
Management Layer: ACID-Transaktionen garantieren Datenkonsistenz, selbst wenn mehrere Prozesse Daten verändern. Schema-Enforcement sorgt für Datenqualität, Versionierung erlaubt Rollbacks und Auditierbarkeit, Data Lineage zeigt exakt, wie Daten entstanden sind.
Processing Layer: Das revolutionäre an der Lakehouse-Architektur ist, dass ein und dieselbe Datenbasis für Batch-Processing, Streaming-Analytics, SQL-Abfragen und Machine Learning genutzt werden kann. Dies eliminiert aufwändige ETL-Prozesse zwischen mehreren Systemen.
Praktische Vorteile: Unternehmen berichten von 60-70% Reduktion der Pipeline-Komplexität, 25-35% niedrigeren Gesamtkosten und wesentlich schnelleren Time-to-Insight für Data Science Teams.
Feature Store: Das Rückgrat des produktiven ML
Wenn Data Mesh, Data Fabric und Lakehouse die Infrastruktur bilden, ist der Feature Store die Schicht, die speziell ML-Systeme optimiert. Ein Feature Store ist ein zentrales Repository für maschinelles Lernen relevante Features – vordefinierte, berechnete Datenaspekte, die in ML-Modellen verwendet werden.
Warum ist ein Feature Store kritisch?
In der Praxis erleben Data Scientists ein klassisches Problem: Die Features, die sie während des Modelltrainings verwenden, unterscheiden sich von denen, die beim Deployment verfügbar sind. Dies führt zum sogenannten Training-Serving Skew, einer häufigen Quelle für degradierende Modellperformance in der Produktion.
Ein Feature Store löst dies durch:
Offline Store: Historische Feature-Daten für Batch-Training und Backtesting.
Online Store: Hochperformante, Low-Latency Speicherung für Echtzeit-Inference (Vorhersagen).
Feature Registry: Zentrale Metadaten-Verwaltung, Versionierung, Dokumentation und Discovery.
Transformation Engine: Automatisierte Pipelines zur Feature-Berechnung, die konsistent zwischen Training und Serving laufen.
Moderne Feature Store Plattformen wie Tecton, Feast und Hopsworks bieten produktionsreife Lösungen für das Management von ML-Features in großem Maßstab.
Point-in-Time Joins und Data Leakage Prevention
Ein zusätzlicher, subtiler aber hochkritischer Vorteil: Feature Stores können sicherstellen, dass bei der Zusammenstellung von Trainingsdaten keine Zukunftsinformation „in die Vergangenheit“ rutscht – ein häufiges Problem, das zu völlig überoptimistischen Modellen führt, die in der Realität versagen.
Real-Time Feature Engineering für zeitkritische KI
Viele moderne KI-Anwendungen brauchen sofortige Entscheidungen: Fraud Detection muss in Millisekunden erkennen, dass eine Transaktion verdächtig ist. Personalisierungssysteme müssen in Echtzeit Nutzerpreferenzen berücksichtigen. Hier kommt Real-Time Feature Engineering ins Spiel.
Die Architektur
Stream Processing: Kontinuierliche Datenverarbeitung mit Tools wie Apache Kafka, Flink oder Spark Streaming, die Events sofort verarbeiten, statt sie zu sammeln und später zu verarbeiten.
Sliding Window Aggregations: Features werden über rollende Zeitfenster berechnet – zum Beispiel der Durchschnitt der Transaktionen der letzten Stunde oder die Anzahl der Logins in den letzten 15 Minuten.
Stateful Computations: Der Kontext zwischen einzelnen Events wird bewahrt – kritisch für Muster-Erkennung oder Anomalieerkennung.
Sub-Second Serving: Feature-Anfragen werden in unter einer Sekunde beantwortet, ermöglichend echtzeitbasierte Entscheidungen.
Herausforderungen
Real-Time Features sind nicht trivial: Daten kommen möglicherweise out-of-order an, Systeme müssen mit Lastspitzen umgehen, und die Feature-Frische muss überwacht werden. Databricks‘ Best Practices für Real-Time Feature Computation adressieren diese kritischen Herausforderungen.
MLOps-Pipelines: Das Nervensystem von KI in der Produktion
MLOps (Machine Learning Operations) ist die Disziplin, die Daten-Pipelines, Model-Training, Deployment und Monitoring in automatisierte, kontinuierliche Workflows integriert. Dies entspricht DevOps, aber speziell für Maschinen-Lernprozesse. MLOps.org legt die Kernprinzipien für die Operationalisierung von Machine Learning Systemen dar.
Kernkomponenten
Data Versioning & Orchestration: Ähnlich wie Versionskontrolle für Code – aber für Daten. Tools wie Apache Airflow orchestrieren komplexe Workflows über mehrere Systeme hinweg.
Model Registry: Trainierte Modelle werden versioniert, dokumentiert und mit Metadaten versehen. Teams können verstehen, welches Modell zu welchen Zeiten in der Produktion lief, und bei Bedarf Rollbacks durchführen.
CI/CD für ML: Continuous Integration und Continuous Delivery – automatisierte Tests, die sicherstellen, dass ein neues Modell nicht schlechter ist als das alte, bevor es deployed wird.
Monitoring & Observability: Permanente Überwachung der Modellperformance, Datenqualität und Drift-Erkennung. Wenn sich die Inputdaten dramatisch ändern, wird das Team proaktiv benachrichtigt.
Architekturvarianten
Lakehouse-basiert: Eine einheitliche Plattform für DataOps, MLOps und ModelOps – alles auf der gleichen physischen Basis.
Lambda/Kappa Architecture: Kombination aus Batch-Processing für historische Analysen und Real-Time Processing für sofortige Insights.
Event-Driven Architecture: ML-Workflows werden durch Events getriggert – zum Beispiel automatisch ein Modell neuertrainieren, wenn neue Trainingsdaten verfügbar sind.
AI Governance und Data Governance Integration
Mit zunehmender KI-Nutzung entsteht eine neue Herausforderung: Wie governance ich KI-Systeme? Dies ist nicht nur ein technisches Problem, sondern ein organisatorisches.
Die neue Governance-Realität
Klassische Data Governance war oft top-down: Ein zentrales Team definierte, was „richtig“ war, zertifizierte bestimmte Datensätze als „golden“ und kontrollierte alles. Dies führte zu Silos und Verzögerungen.
AI + Data Governance 2.0 funktioniert anders:
Federated AI Governance: Dezentrale Teams treffen Entscheidungen mit globalen, automatisierten Policy-Durchsetzungsmechanismen. Ein Data Product Owner entscheidet, wie sein Datensatz definiert wird, muss sich aber an globale Standards halten (z.B. Datenschutz, Compliance).
Real-Time Compliance Monitoring: Automatisierte Systeme überwachen ständig, ob Policies eingehalten werden – Datenzugriffe werden gelogged, verdächtige Muster getriggern Alerts.
Automated Auditability: KI-Systeme erzeugen selbstständig Audit Trails – wer hat auf welche Daten zugegriffen, wie wurden Features definiert, welche Modellversion ist in der Produktion?
Transparency und Explainability: Nicht nur technisch, sondern auch organisatorisch: Stakeholder können verstehen, warum ein ML-Modell eine bestimmte Entscheidung getroffen hat.
Die praktische Umsetzung: Von der Theorie zur Praxis
Schritt 1: Mapping des Ist-Zustands
Bevor irgendetwas implementiert wird, muss eine Organisation verstehen: Wo befinden sich Daten bereits? Welche AI/ML-Systeme existieren bereits? Wo entstehen die größten Silos?
Schritt 2: Identifikation von Domänen
Welche fachlichen Domänen existieren in der Organisation? Diese werden später zu Data Products.
Schritt 3: Auswahl der Technologie-Stack
Data Mesh, Data Fabric und Lakehouse sind Konzepte, nicht konkrete Produkte. Technologien wie Apache Spark, Databricks, Snowflake, dbt, Great Expectations und andere werden kombiniert. Microsofts Azure Architecture Center bietet detaillierte Referenz-Architekturen für den Aufbau von AI/ML-Systemen in der Cloud.
Schritt 4: Pilotprojekte
Nicht die gesamte Organisation auf einmal umstellen, sondern mit einem oder zwei Domänen starten, Lessons Learned sammeln.
Schritt 5: Governance-Framework etablieren
Bevor zu viele AI-Systeme wild durcheinander laufen, ein Governance-Framework aufbauen. Enterprise Architecture Plattformen wie LeanIX unterstützen dabei, Transparenz über AI-Systeme zu schaffen und Governance-Policies durchzusetzen.
Die geschäftlichen Auswirkungen
Unternehmen, die diese modernen Architekturmuster richtig implementieren, berichten von:
-
30-50% schnellere Time-to-Market für neue AI/ML-Produkte
-
40-60% Reduktion der Daten-Engineering-Kosten durch Automatisierung
-
Höhere Datenqualität durch Domain Ownership und dedizierte Data Products
-
Bessere Compliance durch automatisierte, auditierbare Governance
-
Skalierbarkeit: Von wenigen AI-Projekten zu hunderten, während die Komplexität sinkt
Fazit: Die neue Normalität
Die Zukunft des Datenmanagements im KI-Kontext ist dezentralisiert, automatisiert und governance-orientiert. Unternehmen, die noch an monolithischen Data Lakes oder zentralisierten Data Warehouses festhalten, werden nicht mithalten können – nicht wegen der Technologie, sondern weil die Organisationsstruktur nicht skaliert.
Data Mesh, Data Fabric, Lakehouse, Feature Store und MLOps sind nicht nur technologische Spielereien. Sie sind die Enabler für eine Organisation, die AI schnell, skalierbar und verantwortungsvoll nutzen kann. Die Unternehmen, die dies verstanden haben, werden die nächste Dekade prägen.
Die Reise beginnt mit einer ehrlichen Selbstanalyse: Wo steht unsere Organisation heute? Und wo wollen wir morgen sein?


